DynamoDBから特定の値を持つデータを取得する際に、「scan」と「query」の2種類の方法があります。
どちらでもデータを取得するという目的は果たせます。
しかし、わざわざ2つのAPIが用意されているように、これらのAPIは状況によって使い分ける必要があります。
scanAPI
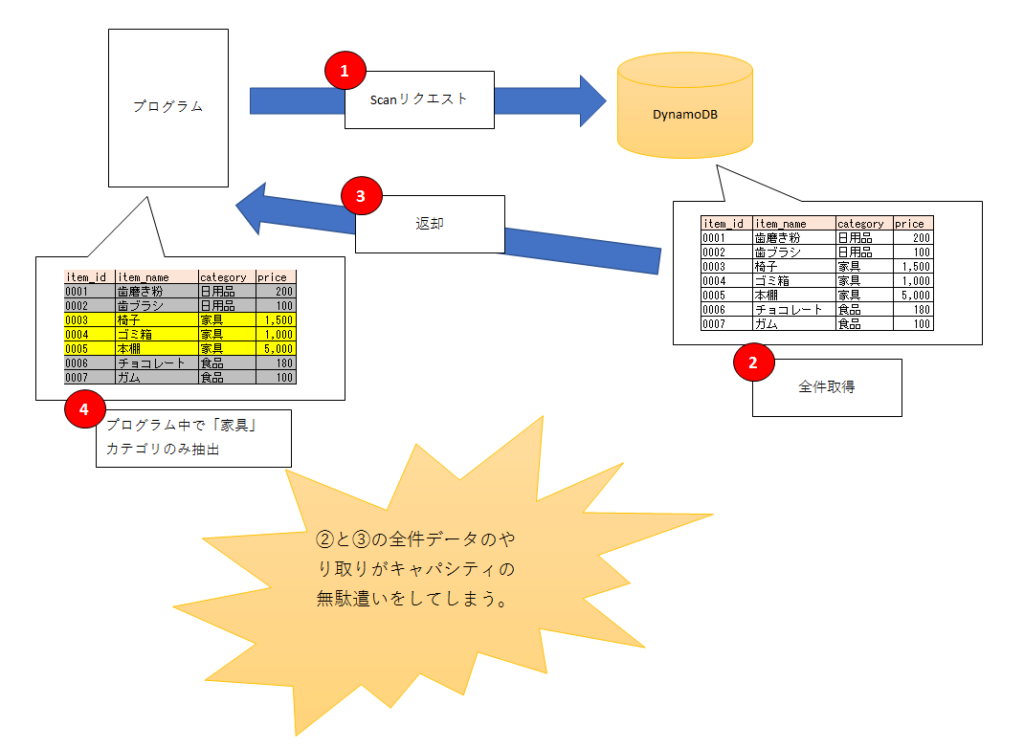
scanは全件走査のAPIです。
つまり、頭からすべてのデータを取得します。
DynamoDBには、キャパシティという概念が存在します。
書き込みキャパシティ、読み込みキャパシティとあり、時間単位当たり決まったデータ量しか読み書きできません。
全件走査であるscanを行うと、このキャパシティを食いつぶしてしまう危険性があります。
scanにも、属性(Attribute)で結果を絞り込むオプションがあります。
しかし、これはあくまで属性であり、Keyではありません。
したがって、「DB上でインデックスを使ってレコードを絞り込む」という動きではなく、「いったん全データを取得した後、プログラム中でフィルタリングを行う」という処理になります。
例えば、必要なデータは数件なのに、データ全体が数万件などある場合は、その数件をとるために毎回数万件のデータの読み込みリクエストを行うことになります。
これは、DynamoDBのキャパシティの無駄遣いとなります。
この無駄遣いを防ぐためには、以下に紹介するqueryAPIを使用する必要があります。
queryAPI
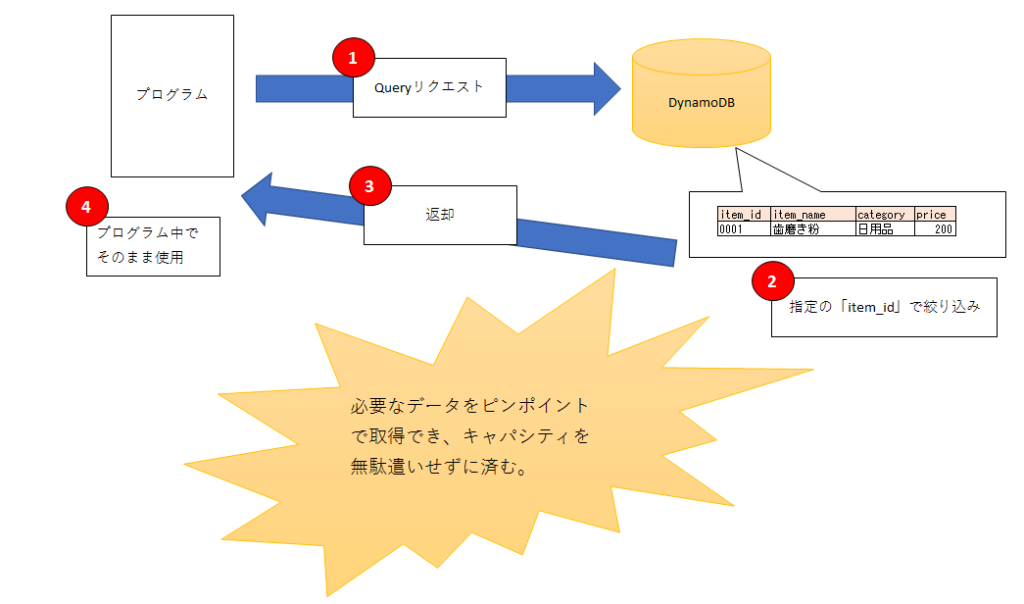
queryAPIもscanと同じで、データを取得するAPIです。
異なるのは、queryがキーを指定できることです。
したがって、プライマリキー、複合プライマリキー、パーティションキー、セカンダリインデックスといったDynamoDBのキーを条件にデータ取得ができます。
例えば、ItemIdをキーとするテーブルがある場合、そのキーのアイテムだけピンポイントで取得することが可能になります。
では、すべての取得処理をqueryで行えばよいのではないかと思うかもしれません。
しかし、queryにも問題はあります。
それは、検索条件に使用できるのがkeyのみだということです。
Attributeを条件にデータ取得をすることはできないのです。
DBなので当たり前ですが、DynamoDBは、keyに指定できる項目数が限られています。
通常は1つ、複合プライマリキーを使用すれば2つ設定することができます。
また、セカンダリインデックスを使用することで、さらに増やすことができます。
とはいえ、keyに指定できる項目数には限界がありますので、なんでもかんでもqueryで取得するというわけにはいきません。
まとめ
scanは、全件取得のAPI。
本当に全件が必要な処理、キャパシティが問題にならない程度のデータ量であれば使用可能。
queryは、条件に合致したデータのみを取得するAPI。
ただし条件に指定できるのはkey(インデックスが設定されている)項目のみ。